一文读懂什么是 RAG (检索增强生成)及相关技术
本文能够解决:
1.快速读懂什么是RAG?
2.了解 RAG 中会用到的技术:分块、向量化、向量数据库、索引
1. 检索增强生成 (RAG) 是什么?
在学习一个新知识,我们首先要理解这个这个东西的本质是什么。
RAG 检索增强生成(Retrieval Augmented Generat)本质上是一个结合了检索和生成两个任务的 LLM 框架。
该框架由两部分构成:向量数据库检索和 LLM 生成。
我们在实际生产过程中,大模型的使用经常会遇到以下几个问题:
1. 知识的局限性:大模型所使用的知识库往往有限,无法覆盖所有场景,而且大模型使用公开的数据训练的,针对公司特定的业务场景,很难回答一些特定的问题。
2. 数据安全性:为了保护公司的隐私数据,我们不能将公司的敏感数据直接上传第三方平台训练通用大模型,但是这样又不能满足公司业务需求。
3. 幻觉问题:大模型的生成是基于概率的,而不是基于事实的,这就导致了大模型生成的内容有时是错误的,我们希望大模型在生成的时候能够根据实际业务场景做一次check。
RAG 检索增强生成,就是将大模型与向量数据库进行结合,从而解决上述问题。
整体的运作模式就是,当用户输入一个问题时,RAG 会先从向量数据库中检索出与问题相关的文档,然后将这些文档作为上下文拼入 prompt 中,输入到大模型中进行生成。
2. RAG 的主要组件
一个完整的 RAG 应用主要包含两个阶段:
1. 数据准备:将私有的数据提取、文本分割、向量化、然后入库,常见的技术框架是 LlamaIndex、Dify等。
2. 检索:将用户输入的问题作为查询条件,在向量库中查询最相似的数据,将检索到的文档作为上下文,常见的数据库有 Chroma、FAISS、Milvus 等,常见的检索方法有
相似性检索:即计算查询向量与所有存储向量的相似性得分,返回得分高的记录。常见的相似性计算方法包括:余弦相似性、欧氏距离、曼哈顿距离等。
全文检索:全文检索是一种比较经典的检索方式,在数据存入时,通过关键词构建倒排索引;在检索时,通过关键词进行全文检索,找到对应的记录。。
3. 生成:大模型根据上下文生成答案。
最终一个prompt的大概长这样:
1 | |
具体流程可参照下图。
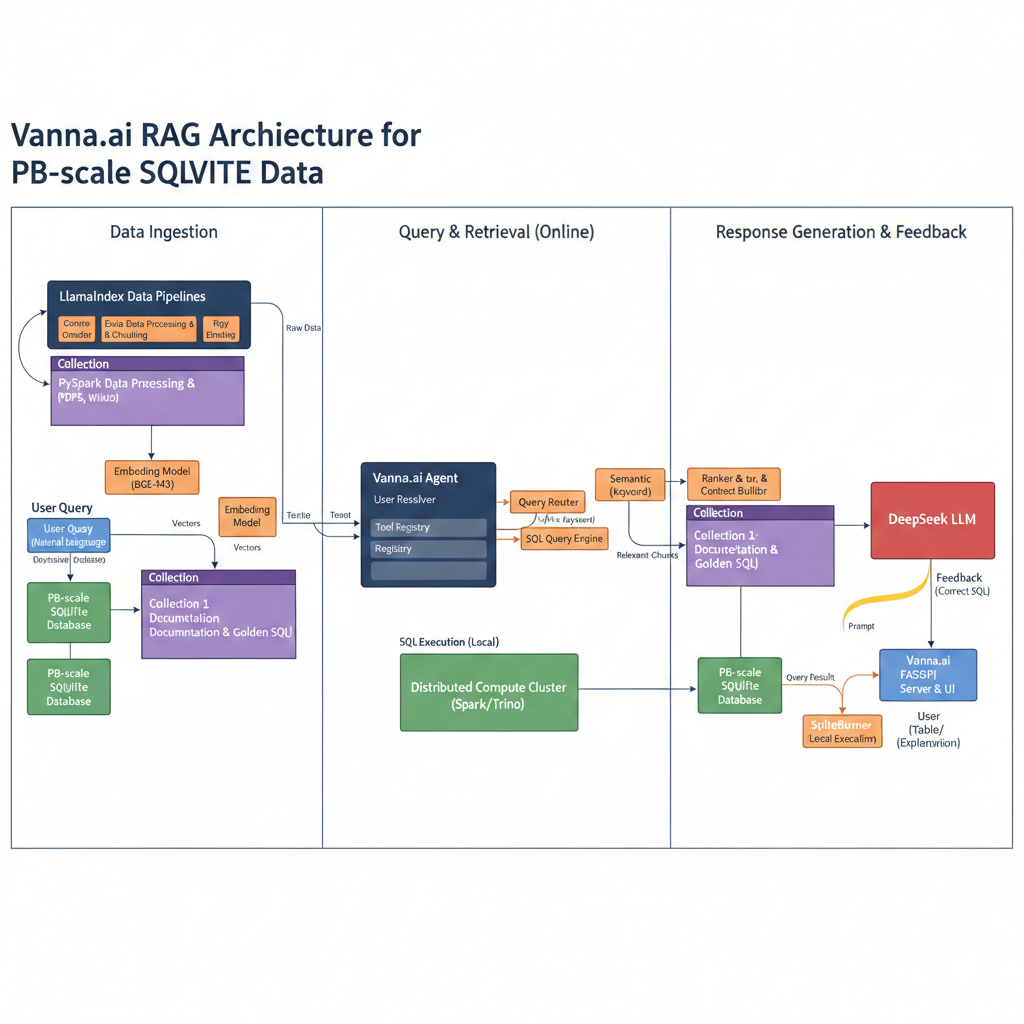
3.具体的技术细节
- 数据的处理:分块和向量化技术:
Transformer 模型有固定的输入长度限制,因此需要将原始数据进行分块(chunk),分块的方式取决于所使用的嵌入模型和模型可以使用的token容量,通常分块较短的嵌入模型更能捕捉细节,较长的嵌入模型更适合总结类型的任务。
常见的技术有:
| 技术类型 | 具体方法 | 适用场景 |
|---|---|---|
| 固定长度分块 | 使用字符数或 Token 数(如每 512 Tokens 一块)。通常配合 10%-20% 的重叠(Overlap) 使用。 | 结构简单的文档、FAQ、初步测试。 |
| 递归字符分块 | 根据层级符号(如 \n\n, \n, , "")尝试切分。 |
最推荐的通用方法。能尽量保持段落和句子的完整性。 |
| 语义分块 | 利用 Embedding 模型计算句子间的相似度,当相似度大幅下降时进行切分。 | 逻辑紧密的叙述、学术文章。确保每一块都是一个独立的主题。 |
| 层级分块 (Parent-Child) | 将文档切成细小的“子块”用于搜索,但在回答时返回它所属的“大父块”。 | 追求极高搜索精度,同时需要丰富上下文的复杂系统。 |
| 特定格式分块 | 针对 Markdown(按标题)、HTML(按标签)或代码(按函数/类)进行切分。 | 开发者文档、代码库、结构化网页。 |
- 向量化
分块之后的数据可以经过embedding向量化,将原始数据映射到向量空间中,向量空间中不同向量的相似度可以表示数据之间的相似性。后续的检索就要通过向量的相似度进行。
常见的技术有:
云端 API (高性能/长上下文):
**OpenAI
text-embedding-3-small/large**:支持高达 8191 Tokens 的窗口,且支持“维度缩减”技术,性价比极高。Voyage AI / Cohere Embed:在特定领域(如代码、财务)检索精度表现卓越。
开源本地模型 (隐私安全/高性能):
BGE 系列 (BAAI):中文检索领域的标杆(如
bge-m3),支持多语言和长文本。GTE 系列 (Alibaba):在 MTEB 排行榜上长期领先,尤其擅长处理长文档。
Jina Embeddings:目前少数支持 8k 甚至更长上下文的开源模型之一。
一个具体的文本 embedding 过程实际上就是 Transformer 的 Encoder 阶段,文本转向量、注入位置编码、通过 Multi-Head Attention 层和 Feed-Forward 层进行处理,最终输出一个向量表示。
以输入 “我爱你” 为例,假设模型维度 $d_{model} = 768$。
- 词法解析阶段 (Tokenization)
原始文本被切分为 Token,并映射为词典中的数字 ID。
- 输入:
"我爱你" - 转换:
[2769, 2302, 872] - 维度:$1 \times 3$ (1行,3个词)
- 初始空间映射 (Input Embedding)
模型内部有一个巨大的权重矩阵(Lookup Table),将离散的 ID 换成连续的向量。
- 计算:每个 ID 去查表,换取一行 768 位的浮点数。
- 注入位置信息:叠加 Position Encoding(位置编码)。
- 维度:$3 \times 768$
状态:此时“我”、“爱”、“你”有了各自的语义,但彼此孤立。
- 全双向交互 (Encoder Self-Attention) —— 核心步骤
这是 Embedding 产生“深度语义”的关键。BERT 类模型不设防,每一层都在做“全员大混战”。
以计算“爱”字在这一层的新向量为例:
- QKV 分裂:
- “爱”产生 $Q_2, K_2, V_2$;“我”产生 $K_1, V_1$;“你”产生 $K_3, V_3$。
- 双向对齐 (Bi-directional Scoring):
- “爱”的 $Q_2$ 与全句所有人进行点积计算:
- $Score_{2,1}$ (爱 $\leftrightarrow$ 我)
- $Score_{2,2}$ (爱 $\leftrightarrow$ 爱)
- $Score_{2,3}$ (爱 $\leftrightarrow$ 你)
- “爱”的 $Q_2$ 与全句所有人进行点积计算:
- 加权融合:
- 将分数通过 Softmax 转化为权重 $\alpha$,对所有人的 $V$ 进行加权求和。
- 结果:新 $V_{爱} = \alpha_1 V_1 + \alpha_2 V_2 + \alpha_3 V_3$
- 维度:依然是 $3 \times 768$
状态:此时的“爱”向量已经理解了它被夹在“我”和“你”之间。
- 纵向特征提纯 (Deep Layers)
上述过程会重复 $L$ 层(如 BERT-base 为 12 层)。
- 底层:提取基础语法和词性特征。
- 高层:提取抽象的意图、情感和逻辑关系。
- 维度:保持 $3 \times 768$。
- 语义归约 (Pooling)
经过多层揉捏后,我们需要把 $3 \times 768$ 的矩阵“压扁”成代表整句话的一个向量。
- 做法一 (CLS):取第一位特殊符号的输出向量(因为它在每一层都全量吸收了全句信息)。
- 做法二 (Mean):对所有位置的向量取平均值。
- 最终维度:$1 \times 768$
对于多模态的embedding方法,基本思路是一致的,只不过是要把图片和图片对应的描述映射到同一个向量
- 向量数据库的运作过程
(常见的向量数据库和他们采用的索引模式)
向量数据库和其他数据库一样,通常分为四层:存储层、索引层、查询层、服务层。
存储层负责存储向量数据,索引层负责建立向量索引,查询层负责响应查询实现查询优化,服务层负责客户端链接和交互等功能。
我们常见的向量数据库有:
Chroma:基于本地存储,支持简单的索引模式(如 Flat Index)。
Milvus:国产之光,支持分布式部署,适用于大规模向量检索。
Pinecone:云端向量数据库,支持实时索引和查询,成本较高。
Weaviate 是一款支持GraphQL的AI集成向量数据库,提供20+AI模块和多模态支持,社区活跃。
向量数据库的工作模式如下:
取:
step1: 查询向量化
当用户输入一个查询的时候,数据库首先会把查询交给embedding模块进行向量化。
step2: 索引
数据库不会和已经存取的向量进行全量对比,而是会使用检索算法结合索引进行快速匹配。具体的检索算法和索引后边会介绍。
step3: 相似度计算
在索引匹配到相似的一部分向量之后,数据库会根据相似度计算算法计算出最相似的向量。
step4: 过滤
数据库会根据元数据过滤掉一部分不和要求的向量,比如说根据存入的时间
同时部分数据库会对向量进行重排序,找到最合适的向量
step5: 返回结果
数据库会返回向量对应的原文、路径、相似度得分。存:
step1: 数据处理
当用户输入数据的时候,数据库会首先将数据交给 embedding 模块进行向量化。
step2: 建立索引
数据库会根据配置建立索引,方便快速定位到相似的向量。数据库会同时存储向量、原始文本、元数据等信息。
step3: 存储
数据库会把向量化后的向量存储起来,等待后续的查询。
4.向量数据库常见的索引算法
📊 常见向量索引算法与底层库对比表
| 类别 | 名称 | 核心原理 | 优势 (Pros) | 劣势 (Cons) | 适用场景 |
|---|---|---|---|---|---|
| 算法 | IVF | 聚类分区:利用 K-Means 将空间划分为小区,搜索时只扫描邻近区域。 | 内存占用低,索引速度快。 | 搜索精度受限于聚类边界。 | 中大规模数据的平衡选型。 |
| 算法 | HNSW | 分层图网络:构建多层“小世界”导航图,通过层级跳跃快速逼近目标。 | 性能巅峰,检索延迟极低,召回率极高。 | 内存消耗巨大,存储成本最高。 | RAG 生产环境、高并发实时检索。 |
| 算法 | PQ | 乘积量化:将长向量切段并压缩为短编码,实现大幅度“瘦身”。 | 极度省空间(可压缩 10-100 倍),检索极快。 | 精度损失明显,存在语义漂移。 | PB 级海量数据的低成本存储。 |
| 算法 | ANNOY | 随机森林/树:通过随机超平面不断二分空间,构建多棵索引树。 | 支持静态文件内存映射(mmap),适合只读。 | 不支持增量更新,必须重新构建索引。 | 静态推荐系统、离线搜索、移动端。 |
| 工具库 | FAISS | 高性能引擎:由 Meta 开发,集成了上述所有算法的底层优化库。 | 支持 GPU 加速,支持多种算法复合(如 IVF-PQ)。 | 仅为工具库,非分布式数据库,需二次开发。 | 向量数据库底层引擎、算法调优。 |
💡 快速选型指南:
- 追求极致性能与准确率 🚀:首选 HNSW(目前 RAG 系统的主流)。
- 数据量巨大但内存预算有限 💰:首选 IVF-PQ 组合。
- 数据几乎不更新且需要低内存读写 🌲:考虑 ANNOY。
- 需要进行亿级数据的大规模训练与加速 🛠️:直接使用 FAISS。
如果想了解更多的技术细节,可以参考!向量数据库常见的索引算法和检索算法
待补充