一文读懂最新的 NL2SQL 组件:Vanna.ai
1. 什么是 Vanna.ai?
Vanna.ai 是一个基于 LLM 的数据查询工具,可以快速查询数据库,并生成 SQL 查询语句。它的核心是基于 LLM 的数据查询工具,可以快速查询数据库,并生成 SQL 查询语句。
它的优势在于,可以将表结构、已经有过的查询语句、文档等等存在一个向量式数据库。等到用户查询的时候,根据用户的查询语句,从数据库中提取出相关的信息,拼入 prompt 中交给 LLM, 让 LLM 生成 SQL 查询语句,进一步将结果可视化,完成后续的问题。
2. 为什么要选用 Vanna.ai?
Vanna.ai 作为 NL2SQL 的一个常见架构。它具有以下几点优势:
安全性:安全性主要体现在两方面。首先,不同的用户可以设置不同的用户组。不同的用户组分开训练向量数据库,admin用户组的查询结构,users用户组无法访问,可以防止用户从历史上下文里边越权获得星系。 其次,vanna.ai 做了很好的解耦,它实际上只是一个 SQL 生成工具,SQL实在自己的系统里边跑的。其他部分 AI 数据插件要求把数据库的链接地址、账号、密码都上传,极有可能发生数据泄漏。
灵活性:Vanna.ai 可以处理多种类型的数据库和查询,适用于不同的应用场景。很多业务分析人员并不了解数据库的结构,Vanna.ai 可以自动生成 SQL 查询语句,帮助非技术人员快速查询数据。
自我学习能力:每次成功的查询和历史对话都会被记录下来,作为后续的学习数据。Vanna.ai 会根据用户的查询和反馈,不断优化自己的模型,提高查询的准确性和效率。
3. Vanna.ai 的主要组件
Vanna.ai 主要有三部分组成,分别是:
执行器官
RunsqlTool:即生产数据库,Vanna.ai 可以连接多种类型的数据库,如 MySQL、PostgreSQL、Oracle、SQL Server 等。记忆器官
ChromaAgentMemory:即向量数据库,Vanna.ai 使用向量数据库来存储数据库中的元数据、历史查询结果、业务相关文档。向量数据库可以快速查找相似
的向量,并返回最相似的向量。每次查询的时候,LLM 会首先在向量数据库中找到与用户查询最相似的向量,然后把向量存储中的信息拼入 prompt 中,交给 LLM,生成 SQL 语句。思考器官
LLM:Vanna.ai 使用 LLM 来生成 SQL 查询语句。LLM 可以理解自然语言,并生成符合语法规则的 SQL 查询语句。
4. Vanna.ai 的架构和运行模式
这里我们参考官方文档给出的流程示意图: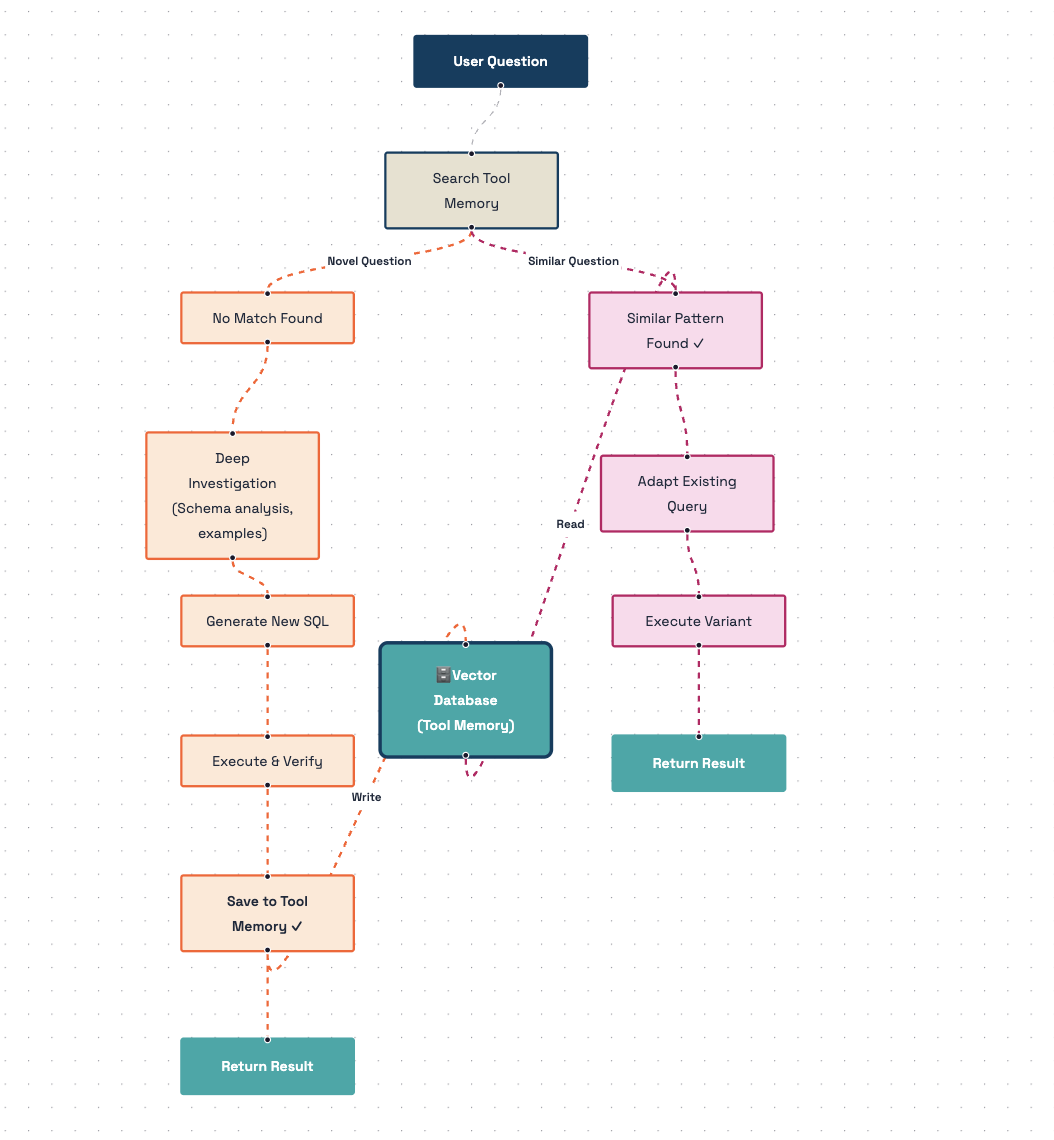
Vanna.ai 的运行模式如下:
用户输入请求:用户提交自然语言问题(如:“广东省 VIP 会员去年的总消费额是多少?”)。
语义向量化 (Embedding):Vanna 调用 Embedding 模型(就是你刚才下载的那个
all-MiniLM),将问题转化为数学向量。知识检索 (RAG Retrieval):Vanna 在向量数据库(你的
chroma.sqlite3)中检索与问题最相关的元数据。检索内容包括:建表语句 (DDL)、业务文档说明、以及历史累积的“问题-SQL”正确对。注入 Prompt:将检索到的“知识”拼入 Prompt,为 LLM 提示数据库的真实结构。SQL 生成 (Text-to-SQL):LLM(如 DeepSeek)结合 Prompt 中的知识,将自然语言逻辑翻译成准确的 SQL 查询语句。
本地执行 (Local Execution):Vanna 的执行器(如
SqliteRunner)在用户本地环境连接数据库并运行 SQL。注意:真实业务数据始终不离开本地。结果处理与可视化:将查询到的数据集(DataFrame)返回给前端,并根据需要调用绘图工具(如 Plotly)生成可视化图表。
反馈与入库 (Feedback Loop):用户或管理员对结果进行评价。如果 SQL 正确且高效,将其作为“金牌案例”存入向量数据库。
持续学习 (Self-Learning):随着正确案例的累积,Vanna 在处理同类问题时会优先匹配历史经验,从而跳过复杂的推理,提高查询的准确率和响应速度。
整体来说Vanna 的核心是一个闭环系统。它通过检索增强(RAG)解决了 LLM 对私有数据库结构的‘信息缺位’问题。在执行端,它通过本地连接器(Runner)确保了数据不外流;在学习端,它通过向量数据库沉淀‘正确 SQL 经验’,实现越用越聪明的良性循环。
大家在做 NL2SQL 时,是倾向于把所有表结构丢给 LLM,还是通过语义检索只给它最相关的 5 张表?欢迎评论区交流。
作为一名大数据开发,我深知“懂业务”与“写代码”之间的鸿沟。Vanna.ai 的出现,不仅仅是省去了重复写 SQL 的时间,更是迈向“数据平民化”的重要一步。
目前我正致力于 NL2SQL 与 Data Agent 的企业级落地。在真实的大数据场景下,要让 AI 真正做到“指哪打哪”,需要一套严密的架构体系。后续我将在博客中持续分享相关的知识沉淀与实战经验,包括深度 RAG 架构优化、SQL 的“自愈”机制 (Self-Correction)、数据安全与动态脱敏、海量元数据的“精排”策略等。
如果你也对 Data + AI 的交叉领域感兴趣,欢迎关注程序员不急 NoRushCoder.com。后续我会持续分享相关的架构思考与技术沉淀,在这个 AI 浪潮奔涌的时代,我们一起“不疾不徐,稳步前行”。